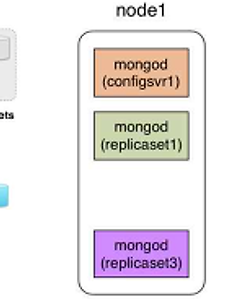
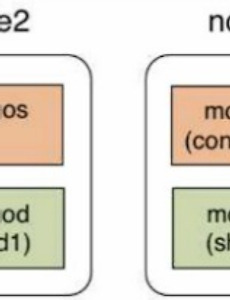
몽고디비5 맥미니 몽고디비 분산 시스템 (5) - Aggregate 1. Sharding을 위한 Shard key 생성Sharding을 위해서는 Shard Key를 생성해야 하며, 생성된 Shard Key에는 반드시 인덱스의 생성이 요구됩니다. $ mongo 192.168.3.2:27017/admin mongos> mongos> db.runCommand( {enablesharding : "test"} ) // test db 의 Shard 기능 활성화 mongos> mongos> use test mongos> db.things.ensureIndex( {empno : 1} ) // empno 항목에 대한 오름차순 색인 생성 mongos> mongos> use admin mongos> db.runCommand( {shardcollection : "test.things", ke.. 2013. 7. 20. 맥미니 몽고디비 분산 시스템 (4) - Replica Set 1. Replica Sets + Sharding 시스템 구성 대용량 처리를 위한 분산 확장이 가능하고 안전성과 높은 가용성 보장을 위해 다음 그림과 같 이 Replica Sets을 구성하고, 이것을 토대로 Sharding 시스템을 구성할 수 있습니다. 4대의 맥미니를 이용하여 Replica Sets + Sharding 시스템을 구성 하는 것을 설명해 드리고자 합니다. 우선 각각의 노드에 다음과 같이 Config 서버와 Replica Set 서버 가 작동하도록 설정해 줍니다. Replica Set1은 모두 10001번 포트를 사용하고, Replica Set2는 모두 10002번 포트를 사용하며, Replica Set3은 모두 10003번 포트를 사용하도록 설정합니다. node1: 192.168.3.1 $ .. 2013. 7. 20. 맥미니 몽고디비 분산 시스템 (3) - Sharding 1. 샤딩Sharding 시스템 구축MongoDB 샤딩 시스템 구축을 위한 개요도는 다음 그림과 같습니다. 3대의 Config 서버와 4대의 Sharding 서버로 구성된 시스템을 만들어 보려 합니다. 위의 그림과 같은 시스템 구성을 위해서는 각각의 node에 접속하여 아래와 같이 설정하면 샤딩 서버와 Config 서버를 구성할 수 있습니다. Config 서버는 각 Shard 서버에 어떤 데이터들이 어떻게 분산 저장되어 있는지에 대한 Meta Data가 저장되어 있으며 MogoS가 데이터를 쓰고/읽기 작업을 수행할 때 Config 서버를 통해서 처리됩니다. in node 1 $ mkdir /data/config1 $ mongod --configsvr --dbpath /data/config1 --port .. 2013. 7. 20. 맥미니 몽고디비 분산 시스템 (2) - 클러스터 구축 준비 1. 맥미니 클러스터의 구성MongoDB를 설치하기 위한 맥미니 클러스터의 구성은 다음과 같습니다. 원활한 설정을 위해서 hostname과, ip address를 제외한 설정은 동일하게 하는 것이 좋습니다. (각 node의 user name은 모두 skyeong로 동일하게 설정합니다.) Hostname IP 용도 제품 성능 node1 192.168.3.1 Config Server Slave Server Name: Mac Mini CPU: 2.6GHz Inte Core i7 Memory: 16GB HDD: 1TB Fusion Drive OS X version: 10.8.3 (mountain lion) node2 192.168.3.2 Shard Server Slave Server node3 192.168.3.. 2013. 7. 20. 맥미니 몽고디비 분산 시스템 (1) - 개요 구글에서 분산컴퓨팅 플랫폼으로 map-Reduce 방식을 제안하면서부터 빅데이터의 저장 및 처리를 위한 기술이 급격하게 발달하고 있습니다. Map-Reduce는 분할-정복 방식으로 대용량 데이터를 병렬로 처리할 수 있는 프로그래밍 모델로, 오픈소스인 Hadoop의 Map-Reduce 프레임워크가 동일한 기능을 제공해 줍니다. MongoDB는 비정형 데이터를 다룰 수 있는 NoSQL 데이터베이스로서, 샤딩Sharding 시스템을 구성함으로써 Map-Reduce 기능을 구현할 수 있습니다.여러대의 컴퓨터에 데이터를 분할해서 저장하겠다는 큰 포부로 컴퓨터를 여러대 구입하다 보면 예산도 이슈가 되지만, 컴퓨터를 쌓아둘 공간이 있는가? 에 대해서도 고민하지 않을 수 없습니다. OS X 기반의 맥미니를 사용한다면 .. 2013. 7. 20. 이전 1 다음