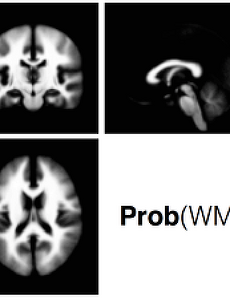
데이터 분석13 뇌영상 데이터 분석 - Create Brain Mask MATLAB을 이용하여 뇌영상 데이터를 분석하다 보면, 뇌영역에 해당되는 부분의 마스크Mask를 만들어야 하는 경우가 있습니다. 이러한 경우에는 뇌영상 데이터 분석 - Matlab Index scheme 강의에서 처럼 MATLAB의 index 기능을 이용하면 회색질, 백색질, 뇌척수액 등에 해당되는 뇌 영역을 indices 값을 얻을 수 있고, 각각의 인덱스 값의 합집합을 이용하면 전체 뇌영역에 해당되는 마스크Mask를 얻을 수 있습니다.위에 그림은 회색질(Grey Matter, GM), 백질(White Matter, WM), 뇌척수액(Cerebro-spinal Fluid, CSF)의 3차원 공간에서의 확률 분포를 보여주고 있습니다. 각각의 영상은 SPM (Statistical Parametric Map.. 2015. 7. 10. 실리콘 밸리에서도 주목받고 있는 토폴로지 데이터 분석 Slideshare를 통해서 토폴로지 데이터 분석(Topological Data Analysis, TDA)에 대한 발표 자료를 2014년 4월에 공유했다. 슬라이드 쉐어에서는 나의 슬라이드를 본 사람들이 어떤 경로로 찾아왔는지에 대한 정보와 어느나라 사람들이 주요하게 관심을 갖고 있는지의 여부를 자동으로 분석해주는 기능이 있어서 한번 살펴봤다.한국 사람중에 나의 슬라이드를 본 사람들은 대부분 얼굴책 등에서 내가 공유한 것을 보고 링크를 타고 온 사람들이라고 생각된다. 하지만 미국이나 독일에서 슬라이드를 본 사람은 분명히 검색을 통해서 나의 토폴로지 데이터 분석 슬라이드를 찾았을 것이다. 또한, 아래 그림 중에서 국가별로 슬라이드를 '본 사람 수'의 그래프에서도 볼 수 있듯이 토폴로지 분석은 미국, 독일,.. 2015. 3. 18. Contrasts in Neuroimaging Data Anlaysis SPM 등의 뇌영상 데이터 분석 툴을 이용한 뇌영상 데이터의 분석은 기본적으로 각 복셀의 영상에 할당된 데이터 값을 일반 선형 모델 (General Linear Model, GLM)을 이용하여 모델링하고, 실제 데이터와 모델이 얼마나 잘 맞는지 통계적으로 테스트 하는 것이다. 특정 복셀 $i$에 대해서 $Y_{i} = XB_i + E_i$로 모델링 했을때 $X$는 디자인 행렬이되고, 벡터 $B_i$는 분석을 통해서 추정되는 파라미터이며, $E_i$는 에러를 의미한다. 이때 contrast는 $c'B$를 통해서 계산된다. 뇌영상 데이터에서 $c$는 보통 행벡터(column vector)를 의미하고, $c$를 통해서 다양한 contrasts로 결과를 확인할 수 있다. 벡터 $c$는 contrasts의 가중치.. 2015. 3. 15. smoothness estimation in SPM and AFNI Smoothness estimation은 MonteCarlo simulation을 위해서 반드시 필요한 과정입니다. SPM으로 영상 데이터를 분석했다면, SPM.mat 파일의 Field 값을 확인함으로써 smoothness를 확인할 수 있습니다. >>load SPM; % SPM 결과 파일이 저장된 폴더에서 실행 >>M = SPM.xVol.M; % 변환행렬 정보를 가져옴 >>VOX = abs(diag(M)); % 대각행렬 정보가 볼셀 사이즈 >>FWHM = SPM.xVol.FWHM; % FWHM in voxel unit >>FWHMmm = FWHM.*VOX(1:3)'; % FWHM in mm unit >>disp(FWHMmm); SPM에서 Gaussian random field theory를 기반으로 sm.. 2015. 1. 23. Voxel size determination through the MonteCarlo Simulation in AFNI 뇌영상을 이용한 뇌과학 연구는 대부분 다음과 같은 질문에 답하는 것이다.3차원의 뇌에 어떤 영역이 활성화 되었는지? 특정 영역의 시계열 데이터와 상관성이 높게 나오는 뇌영역은 어디인지? 생물정보학에서 다루는 Microarray 데이터도 마찬가지 이지만, 뇌영상 데이터도 multiple comparison에서 발생하는 false positive를 조절하는 방법에 대해서다양한 해법들이 있다. 가령, false discovery rate (FDR) 또는 family-wire error rate (FWE) 등이 전통적으로 가장 많이 이용되어 왔던 multiple comparison correction 방법들이다. 뇌영상 데이터는 특정 복셀에서 통계적으로 유의미한 차이를 보인다고 했을때 "아, 이 볼셀에서 통계적.. 2015. 1. 7. Topological Data Analysis를 이용한 전국 지방자치단체의 토건예산, 복지예산, 자살률의 관계 분석 Topological Data Analysis 방법에 대해 궁금한 사항은 Slideshare를 통해서 공개된 자료를 참고해 주시면 되고, 여러 논문들에서도 방법을 확인하실 수 있습니다. 뉴스타파는 제가 제일 신뢰하는 언론이기에 뉴스타파 홈페이지를 자주 방문하곤 합니다. 전국 242개 지방자치단체 토건예산, 복지예산, 자살률 자료가 공개 된지는 두어달 전이지만, 그동안 그냥 눈팅만 하다가 이제야 데이터를 직접 분석해 보기로 했습니다. Topological Data Analysis (이하 TDA)는 데이터 간의 거리 정보를 이용하여 데이터 간에 관계를 분석하는 기법으로 순수 수학인 '위상수학'에 뿌리를 두고 있습니다. 데이터 분석을 위해서 사용한 데이터는 2009년 복지예산과 토건예산의 비율, 2012년 복.. 2014. 7. 26. 이전 1 2 3 다음