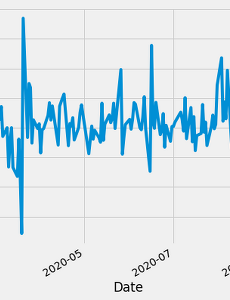
데이터분석7 시계열 안정성 테스트 - ADF and KPSS 테스트 (feat. 파이썬) 앞서 시계열 데이터 분석 및 예측을 위한 완벽 가이드에서 시계열 데이터 분석에 있어 데이터의 안정성(Stationary)을 확인하는 것이 중요함을 소개해 드렸습니다. 이번에는 파이썬으로 ADF (Augmented Dickey-Fuller) 테스트와 KPSS (Kwiatkowski–Phillips–Schmidt–Shin) 테스트를 수행하는 방법에 대해서 설명해 드리겠습니다. 라이브러리 Import import pandas as pd import matplotlib.pyplot as plt plt.style.use('fivethirtyeight') 시계열 데이터는 야후 파이낸스에서 가져오겠습니다. 만약 yfinance 라이브러리가 설치가 안되었다면, 아래의 명령어를 통해서 설치해 주세요. !pip insta.. 2020. 12. 25. 고차원 데이터의 차원 축소와 시각화 방법 (PCA vs. t-SNE) 데이터분석과 관련하여 가장 중요한 것은 데이터가 어떻게 생겼는지 탐색하는 과정입니다. 이 과정에 데이터의 특정 변수의 분포를 관찰할 수도 있고, 서로 상관관계가 있는 변수들이 어떻것이 있는지 살표보는 과정이 있을 수도 있다. 하지만, 최근에는 데이터셋이 갖고 있는 변수의 숫자가 늘어남에 따라서 몇몇 특정 변수의 분포를 살펴보는 것으로 데이터를 탐색한다고 말하기가 어려운 상황입니다. 고차원의 데이터로부터 핵심적인 정보를 추려내고 시각화 한 후에야 데이터가 어떤 특징을 갖고 있는지 탐색하는게 가능합니다. 이러한 문제점을 해결해 줄 수 있는 방법으로 고차원 데이터의 차원을 줄여서 시각화 하는 기술은 매우 중요합니다. 이러한 기술로 주성분분석(Principle Component Analysis, PCA)와 t-.. 2020. 12. 25. 뇌영상 데이터 분석 - Create Brain Mask MATLAB을 이용하여 뇌영상 데이터를 분석하다 보면, 뇌영역에 해당되는 부분의 마스크Mask를 만들어야 하는 경우가 있습니다. 이러한 경우에는 뇌영상 데이터 분석 - Matlab Index scheme 강의에서 처럼 MATLAB의 index 기능을 이용하면 회색질, 백색질, 뇌척수액 등에 해당되는 뇌 영역을 indices 값을 얻을 수 있고, 각각의 인덱스 값의 합집합을 이용하면 전체 뇌영역에 해당되는 마스크Mask를 얻을 수 있습니다.위에 그림은 회색질(Grey Matter, GM), 백질(White Matter, WM), 뇌척수액(Cerebro-spinal Fluid, CSF)의 3차원 공간에서의 확률 분포를 보여주고 있습니다. 각각의 영상은 SPM (Statistical Parametric Map.. 2015. 7. 10. 뇌영상 데이터 분석 - Matlab Index scheme 매틀랩으로 데이터 분석을 하다보면 find() 명령어를 통해서 특정 index를 찾고, 해당되는 index 값에 대해서만 여러 연산을 수행하는 과정이 필요합니다. 매틀랩에서 행렬을 생성하게 되면 아래의 그림과 같이 Subscript space에서는 A(1,1) 또는 A(1,2) 등의 과정을 통해서 행렬의 각 요소에 있는 값을 얻어올 수 있습니다. 하지만, Subscript space에서 Index space로 변환을 하게 되면 A(1,1)은 A(1)로 접근이 가능하고, A(1,2)는 A(11)을 통해서도 행렬의 값을 얻을 수 있습니다. 가령 아래와 같은 10x20의 행렬 A를 생각해 보겠습니다. 숫자는 행렬의 index를 의미하는 것이고 색깔은 행렬 요소의 값을 의미합니다. 파란색은 0이고 빨간색은 1을.. 2015. 6. 25. Topological Data Analysis with R, (토폴로지 데이터 분석) 국가수리과학연구소에서 병역특례로 근무하는 동안 (2011-2014) 다양한 수학자들을 만나 수 있었습니다. 그 중에서 위상수학(Topology)를 공부하신 박사님과 한 팀에서 일을 할 수 있게 되었는데, 이때 처음으로 토폴로지 데이터 분석 (Topological Data Analysis, TDA)라는 방법을 알게 되었습니다. 토폴로지 데이터 분석의 핵심은 고차원 위상공간의 매니폴드에서 얻은 포인트 클라우드 데이터를 간단하게 추상화 하여 그래프의 형태로 표현하는 것입니다. Filtration에 의해서 샘플된 데이터는 Simplicies를 구성하기 위해 사용되고, 이거한 simplicies들을 선으로 연결하여 매니폴드를 추상화 합니다. 또한, 대수적 토폴로지(Algebraic Topology)를 이용하면 여.. 2015. 2. 27. Slice Timing Correction 하나의 3차원 뇌영상 데이터는 여러개의 단면영상(Slice Image)으로 구성되어 있다. 기능자기공명영상(functional magnetic resonance imaging, fMRI)의 경우에는 보통 매2초마다 하나의 3차원 볼륨 영상을 획득하게 된다. 다시 말해서 2초동안 여러개의 단면영상을 획득하게 되는데, 그중에서 제일 처음에 획득한 단면영상과 맨 마지막에 획득한 단면영상 간에는 최고 2초 정도의 시간 차이가 발생하게 된다. 이러한 시간 차이를 보정해 주는 것이 Slice timing correction이라 물리는 전처리 과정이다. SPM의 경우에 slice timing correction 을 적용하게 되면 'a'를 어두로 하는 새로운 뇌영상 파일이 생성된다. 단면영상의 순서(slice orde.. 2015. 2. 12. 이전 1 2 다음