Prophet는 비선형 추세가 연도 별, 주별, 일별, 계절 성과, 그리고 휴일 효과에 반영할 수 있는 시계열 모형입니다. 계절적 효과가 강하고 여러 시즌의 과거 데이터가 있는 시계열에서 가장 잘 작동합니다. Prophet은 누락된 데이터와 추세 변화에 강하며 일반적으로 이상 값을 잘 처리합니다. Prophet은 Facebook의 핵심 데이터 사이언스팀에서 출시한 오픈 소스 소프트웨어입니다. CRAN 및 PyPI에서 다운로드 할 수 있습니다.
예측은 조직의 업무 계획, 목표 설정, 그리고 이상 탐지에 활용할 수 있는 데이터 사이언스 과제입니다. 하지만, 이러한 중요성에도 불구하고 신뢰할만한 고품질의 예측을 생성하는 것은 매우 어려운 일입니다. 또한, 시계열 모델링에 대한 전문 지식이 있는 분석가가 많지 않다는 것도 업계가 처한 가장 큰 현실적 어려움입니다.
Prophet은 이러한 문제를 해결하기 위해서 다양한 모델을 구성하고 성능 분석을 결합한 "대규모" 예측에 대한 실용적인 접근 방식을 추구합니다. 시계열에 대한 도메인 지식이있는 분석가가 직관적으로 조정할 수있는 해석 가능한 매개 변수가있는 모듈식 회귀 모델을 제안합니다. 성능 분석을 설명하여 예측 절차를 비교 및 평가하고 수동 검토 및 조정을 위해 예측에 자동으로 플래그를 지정합니다. 분석가가 자신의 전문 지식을 가장 효과적으로 사용하는데 도움이되는 분석 도구를 사용한다면 시계열을 안정적이고 실질적으로 예측할 수 있습니다.
Prophet은 일반적으로 다음과 같은 특징이있는 Facebook에서 만난 비즈니스 예측 작업에 최적화되어 있습니다.
- 최소 몇 달 (바람직하게는 1 년)간의 기록이 있는 시간별, 일별 또는 주별 관찰
- 여러 "Human-scale" 계절성 : 요일 및 연중 시간
- 불규칙한 간격으로 발생하는 중요한 휴일(예: 슈퍼 볼)
- 합리적인 수의 누락된 관측치 또는 큰 이상치
- 예를 들어 제품 출시 또는 로깅 변경으로 인한 과거 추세 변화
- 추세가 자연적인 한계에 도달하거나 포화되는 비선형 성장 곡선인 추세

Prophet을 구성하는 4가지 주요 항목
Prophet 프로시저는 4가지 주요 구성 요소가 있는 가법(additive) 회귀 모델입니다.
- 부분 선형 또는 물류 성장 곡선 추세. Prophet은 데이터에서 변경점을 선택하여 추세의 변화를 자동으로 감지
- 푸리에 급수를 사용하여 모델링 된 연간 계절 성분
- 더미 변수를 사용하는 주간 계절 성분
- 사용자가 제공 한 중요한 공휴일 목록
Prophet 설치
Prophet을 사용하기 위해서는 베이지안 분석 라이브러리인 pystan과 페이스북에서 개발한 fbprophet을 설치해야 합니다. pystan 설치에 대해 자세한 사항은 링크를 통해서 확인할 수 있습니다.
!pip install pystan
!pip install fbprophet
라이브러리 Import
import pandas as pd
import numpy as np
from fbprophet import Prophet
import pandas_datareader.data as web
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')주가 데이터 가져오기
pandas_datareader 라이브러리를 이용해서 주가 데이터를 가져오겠습니다.
start = '2018-01-01'
end = '2020-12-31'
ticker = 'LAC'
df = web.DataReader(name=ticker, data_source='yahoo', start=start, end=end)
# Prophet Inputs: ds(날짜), y(주가데이터)
df['ds'] = pd.to_datetime(df.index, format='%Y-%m-%d')
df['y'] = df['Close']
df = df[['ds','y']]
print(df)
주가 데이터 시각화
# Select 'y' columns to plot
ax = df['y'].plot(title=ticker, figsize=(12,8))
ax.set_ylabel('Close price (Won)')
plt.show()
모델 적합
# Fit the model - df-Apple
df_prophet = Prophet(changepoint_prior_scale=0.15, daily_seasonality=True)
df_prophet.fit(df)향후 1년간의 time stamp 생성
예측을 위해서는 예측하고자 하는 날짜가 'ds' 컬럼에 있어야 합니다. Prophet.make_future_dataframe을 사용하여 지정된 날짜 수만큼 미래로 확장되는 적절한 데이터 프레임을 얻을 수 있습니다. 기본적으로 모형의 훈련에 사용된 시계열의 날짜도 포함되므로 모델이 맞는지 확인할 수 있습니다.
fcast_time = 90 # 1 year: 365
df_forecast = df_prophet.make_future_dataframe(periods = fcast_time, freq = 'D')
df_forecast.tail(10)
predict 메서드를 이용한 주가 예측
predict 메서드는 예측하고자 하는 미래의 각 날짜에 yhat이라는 예측 값을 계산해 줍니다. 과거 날짜를 입력하면 샘플내 적합 결과를 제공합니다. 여기서 예측 개체는 예측이 포함 된 yhat 열과 구성 요소 및 불확실성 구간에 대한 열을 포함하는 새로운 데이터 프레임입니다.
# Forecasting - call the method predict
df_forecast = df_prophet.predict(df_forecast)예측 결과 확인
df_forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail()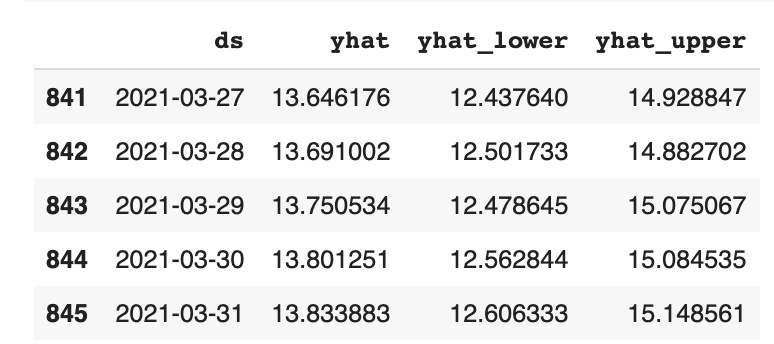
예측값 시각화
df_prophet.plot(df_forecast, xlabel = 'Date', ylabel = 'Price ($)')
예측 구성요소 확인
예측에 사용된 구성 요소는 Prophet.plot_components 메서드를 사용해서 확인할 수 있습니다. 기본적으로 시계열의 추세, 연간 계절성, 그리고 주간 계절성이 표시됩니다.
fig2 = df_prophet.plot_components(df_forecast)
plt.show()
교차검증 분석
교차 검증 절차는 cross_validation 함수를 사용하여 과거 컷오프 범위에 대해 자동으로 수행됩니다. 예측 기간(horizon)을 지정한 다음 선택적으로 초기 훈련 기간(initial)의 크기와 컷오프 날짜 사이의 간격(period)을 지정합니다. 기본적으로 초기 훈련 기간은 horizon의 3배로 설정되며, cutoff는 수평선의 절반마다 이루어집니다.
cross_validation의 출력은 각 시뮬레이션된 예측 날짜와 각 컷오프 날짜에 대해 실제 값(=y)과 표본 외 예측 값(=yhat)을 갖는 데이터 프레임입니다. 특히 컷오프와 컷오프 + 수평선 사이의 모든 관측 지점에 대해 예측이 이루어집니다. 이 데이터 프레임은 yhat과 y값 사이의 오류를 측정하는데 사용할 수 있습니다.
여기서 우리는 첫 번째 컷오프에서 730일의 훈련 데이터로 시작하여 180일마다 예측을 수행하여 365일 범위에서 예측 성능을 평가하기 위해 교차 검증을 수행합니다. 이 8년 시계열에서 이는 총 11개의 예측에 해당합니다.
from fbprophet.diagnostics import cross_validation
df_cv = cross_validation(df_prophet, initial='1095 days', period='180 days', horizon = '365 days')
df_cv.head()
모형 성능 확인
performance_metrics 유틸리티는 컷오프로부터의 거리(예측이 얼마나 빗나갔는지)의 함수로 예측 성능 (y에 비해 yhat, yhat_lower 및 yhat_upper)의 유용한 통계를 계산하는 데 사용할 수 있습니다. 계산된 통계는 평균 제곱 오차(MSE), 제곱 평균 오차(RMSE), 평균 절대 오차(MAE), 평균 절대 백분율 오차(MAPE), yhat_lower 및 yhat_upper 추정치의 범위입니다.
from fbprophet.diagnostics import performance_metrics
df_p = performance_metrics(df_cv)
df_p.head()
교차검증 결과 시각화
from fbprophet.plot import plot_cross_validation_metric
fig = plot_cross_validation_metric(df_cv, metric = 'mae')
'데이터과학 > 데이터 분석 실습' 카테고리의 다른 글
| 기계 학습 기반의 신용평가 모형 개발과 신용 점수 계산 (1) | 2021.01.20 |
|---|---|
| AWS SageMaker를 이용해서 모델 빌드, 배포, 예측하기 (2) | 2021.01.19 |
| SQL 쿼리, 파이썬 Pandas로 한다면? (1) | 2021.01.03 |
| 실제 강도 지수를 이용한 알고리즘 트레이딩 (feat. 파이썬) (1) | 2020.12.31 |
| 스토캐스틱 지표를 이용한 알고리즘 투자전략 (feat. 파이썬) (0) | 2020.12.30 |



