신용 점수는 사람들의 신용도를 측정하여 숫자로 표현한 것입니다. 은행은 일반적으로 신용 신청에 대한 의사 결정을 위해 이 점수를 활용합니다. 이 블로그에서는 고객의 신용도를 측정하기 위해 가장 인기 있고 가장 간단한 신용 점수 형식인 표준 스코어 카드를 Python (Pandas, Sklearn)을 사용하여 개발하는 방법에 대해 설명하겠습니다.

프로젝트 동기
오늘날 신용도는 개인을 얼마나 신뢰할 수 있는지 나타내는 지표로 간주되기 때문에 모든 사람에게 매우 중요합니다. 다양한 상황에서 서비스 공급자는 먼저 고객의 신용을 평가한 다음 서비스 제공 여부를 결정합니다. 그러나 전체 개인 포트폴리오를 확인하고 신용 보고서를 수동으로 생성하려면 시간이 많이 걸립니다. 따라서 신용을 점수로 계산하면 시간을 절약하고 쉽게 이해할 수 있기 때문에, 신용을 평가하는데 신용 점수가 많이 사용되고 있습니다.
신용 점수를 생성하는 과정을 "Credit Scoring"이라고 합니다. 많은 산업, 특히 은행에서 널리 사용됩니다. 은행은 일반적으로 이 정보를 사용하여 신용 대출을 받아야하는 사람, 신용대출 승인 금액, 신용 위험을 줄이기 위해 취할 수 있는 운영 전략을 결정합니다. 일반적으로 두 가지 주요 부분이 있습니다.
- 통계 모델 구축
- 통계 모델을 적용하여 신용 신청 또는 기존 신용 계정에 점수 할당
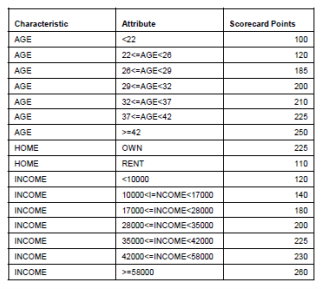
여기서는 스코어 카드라는 가장 인기있는 신용 평가 방법을 소개합니다. 스코어 카드가 신용 스코어링을 위한 가장 일반적인 방법으로 사용하는데 두 가지 주요 이유가 있습니다. 첫째, 의뢰인 등 관련 배경과 경험이없는 사람들에게도 쉽게 해석 할 수 있습니다. 둘째, 스코어 카드의 개발 프로세스는 표준이며 널리 이해되고 있으므로 회사에서 많은 비용을 지출 할 필요가 없습니다. 다음은 샘플 스코어 카드입니다. 나중에 사용 방법에 대해 이야기하겠습니다.
데이터 탐색 및 피쳐 엔지니어링
이제 스코어 카드를 개발하는 방법에 대해 자세히 설명하겠습니다. 여기에서 사용한 데이터 세트는 Kaggle 대회에서 가져온 것입니다. 자세한 정보는 그림2에 나와 있습니다. 첫 번째 변수는 이진 범주형 변수인 대상 변수입니다. 나머지 변수는 피쳐 입니다.
데이터 세트에 대한 통찰력을 얻은 후 몇 가지 피쳐 엔지니어링 방법을 적용하기 시작합니다. 먼저 각 특성에 누락된 값이 있는지 확인한 다음 누락된 값을 중앙값으로 대체합니다.

다음으로 이상치를 처리 합니다. 특이치를 처리하는 방법은 특이치 유형에 따라 다릅니다. 예를 들어 이상 값이 측정 중 기계적 오류 또는 어떤 문제로 인한 경우 누락된 데이터로 처리 할 수 있습니다. 이 데이터 세트에는 매우 큰 값이 있지만 모두 합리적인 값입니다. 따라서 나는 그들을 처리하기 위해 상단 및 하단 코딩을 적용합니다. 그림3에서 상단 코딩을 적용한 후 피쳐 분포가 더 정상적임을 알 수 있습니다.

그림1에 표시된 샘플 스코어 카드에 따르면 각 기능은 다양한 속성 (또는 그룹)으로 그룹화되어야 합니다. 피쳐를 그룹화하는 데에는 몇 가지 이유가 있습니다.
- 피쳐 및 성능의 관계 속성에 대한 통찰력을 얻으십시오.
- 비선형 종속성에 선형 모델을 적용합니다.
- 포트폴리오 관리를 위한 더 나은 전략을 개발하는데 도움이 될 수있는 위험 예측자의 행동에 대해 더 깊이 이해합니다.
비닝은 이러한 목적으로 사용되는 적절한 방법입니다. 처리 후 각 값을 있어야하는 속성에 할당합니다. 즉, 모든 숫자 값이 범주 형으로 변환됩니다. 다음은 비닝 결과에 대한 예입니다.

모든 피쳐를 그룹화하면 피쳐 엔지니어링이 완료됩니다. 다음 단계는 각 속성에 대한 증거의 가중치와 각 특성 (또는 특징)에 대한 정보 값을 계산하는 것입니다. 앞서 언급했듯이 모든 숫자값을 범주형으로 변환하기 위해 비닝을 사용했습니다. 그러나 이러한 범주형 값으로 모델을 맞출 수 없으므로 이러한 그룹에 일부 숫자 값을 할당해야합니다. WoE (Weight of Evidence)의 목적은 정확히 각 범주형 변수 그룹에 고유한 값을 할당하는 것입니다. 정보 값 (Information Value, IV)은 피쳐 선택에 사용되며 해당 피쳐의 예측력을 측정합니다. WoE 및 IV의 공식은 다음과 같습니다. 여기서 "양호"는 고객이 심각한 연체가 발생하지 않거나 목표 변수가 0과 같음을 의미하고, "나쁨"은 고객이 심각한 연체를 겪거나 목표 변수가 1임을 의미합니다.

일반적으로 특성 분석 보고서는 WoE 및 IV를 얻기 위해 생성됩니다. 여기에서는 보고서를 자동으로 생성하는 Python 함수를 정의합니다. 예를 들어“연령”에 대한 특성 분석 보고서는 그림5와 같습니다.

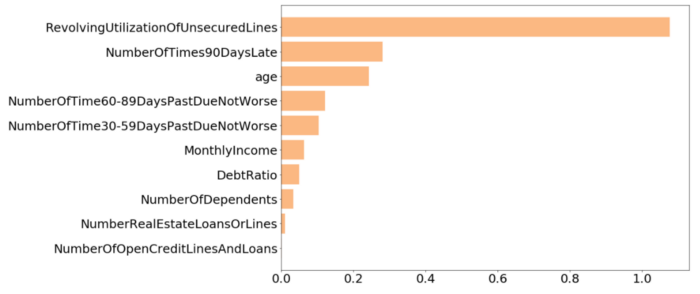
그런 다음 모든 피쳐의 IV를 비교하기 위해 막대 차트를 만듭니다. 막대 차트에서 "NumberOfOpenCreditLinesAndLoans" 및 "NumberRealEstateLoansOrLines"의 마지막 두 기능이 IV가 매우 낮다는 것을 알 수 있으므로 여기에서는 모델 피팅을 위해 다른 8개 기능을 선택합니다.
모델 피팅 및 스코어 카드 포인트 계산
기능 선택 후 속성을 해당 WoE로 바꿉니다. 지금까지 모델 학습에 적합한 데이터 세트를 얻었습니다. 스코어 카드 개발에 사용되는 모델은 이진 분류에 널리 사용되는 모델인 로지스틱 회귀입니다. 교차 검증 및 그리드 검색을 적용하여 매개 변수를 조정합니다. 그런 다음 테스트 데이터 세트를 사용하여 모델의 예측 정확도를 확인합니다. 데이터 처리의 효과를 보여주기 위해 원시 데이터와 처리된 데이터로 모델을 훈련합니다. Kaggle이 제공한 결과에 따라 데이터 처리 후 정확도가 0.693956에서 0.800946으로 향상되었습니다.
마지막 단계는 각 속성에 대한 스코어 카드 포인트를 계산하고 최종 스코어 카드를 생성하는 것입니다. 각 속성에 대한 점수는 다음 공식으로 계산할 수 있습니다.
- 신용 점수 = (β × WoE + α / n) × 요인 + 오프셋 / n
- β — 주어진 속성을 포함하는 특성에 대한 로지스틱 회귀 계수
- α — 로지스틱 회귀 절편
- WoE — 주어진 속성에 대한 증거 가중치 값
- n — 모델에 포함된 피쳐의 수
- 요인, 오프셋 — 배율 매개 변수
계수 및 오프셋을 계산하는 데 다음 공식이 사용됩니다.
- 인자 = PDO / Ln (2)
- 오프셋 = 점수 — (요인 × ln (배당률))
여기서 PDO(points of double odds)는 odds 값을 두 배로 늘리는 점을 의미하며 위의 특성 분석 보고서에서 이미 불량률이 계산되었습니다. 스코어 카드의 기본 odds 값이 600점에서 50:1이고 PDO가 20인 경우 (20 점마다 두 배가 될 확률) 계수 및 오프셋은 다음과 같습니다.
- 계수 = 20 / ln(2) = 28.85
- 오프셋 = 600- 28.85 × ln(50) = 487.14
모든 계산이 끝나면 스코어 카드 개발 프로세스가 완료됩니다. 스코어 카드의 일부는 그림7에 나와 있습니다.

새로운 고객이 올 때 데이터에 따라 각 특성에서 올바른 속성을 찾고 점수를 얻으면됩니다. 최종 신용 점수는 각 특성의 점수 합계로 계산할 수 있습니다. 예를 들어, 나이가 45세이며, 부채 비율 0.5, 월 소득 5000 달러인 고객이 신용 카드를 새로 신청했을때 신용 점수는 53 + 55 + 57 = 165로 계산될 수 있습니다
보다 정확한 스코어 카드를 개발하려면 일반적으로 더 많은 상황을 고려해야합니다. 예를 들어, "나쁨"으로 식별된 어떤 고객은 신청이 승인될 수도 있는 반면, 승인이 거부된 "좋은"사람이 있을 수도 있습니다. 따라서 거부 추론이 개발 프로세스에 포함되어야 합니다. 데이터에 없는 거부된 케이스의 데이터 세트가 필요하기 때문에 이번 블로그에서 이 부분을 수행하지 않겠습니다. 이 부분에 대해 더 자세히 알고 싶다면 Naeem Siddiqi의 저서 Credit Risk Scorecards — Developing and Implementing Intelligent Credit Scoring을 읽어 보시기 바랍니다.
참고) 이 블로그의 원문은 아래 링크에서 읽어보실 수 있습니다.
link.medium.com/itkhPK2xbdb
Credit Scoring with Machine Learning
The credit score is a numeric expression measuring people’s creditworthiness. The banking usually utilizes it as a method to support the…
medium.com
'데이터과학 > 데이터 분석 실습' 카테고리의 다른 글
| LSTM 또는 CNN을 이용한 주가 예측 (1) | 2021.01.31 |
|---|---|
| 머신 러닝 기반의 금융 사기 탐지: 불균형 데이터를 다루는 방법 (0) | 2021.01.23 |
| AWS SageMaker를 이용해서 모델 빌드, 배포, 예측하기 (2) | 2021.01.19 |
| Prophet을 이용한 주가 예측 (0) | 2021.01.04 |
| SQL 쿼리, 파이썬 Pandas로 한다면? (1) | 2021.01.03 |



