LSTM은 보통 순차 데이터의 이동 알고리즘으로 간주되어 왔으며 CNN은 보통 이미지 데이터 처리를 위한 최고의 알고리즘으로 간주되었습니다. LSTM 또는 기타 Recurrent Neural Network (RNN)와 동등하거나 더 나은 문자 수준 CNN의 사용에 대한 많은 논문이 출판되었습니다.
이 가설을 테스트하기 위해 두가지 알고리즘을 시계열 분석의 전형적인 사례인 주가 예측에 구현해보겠습니다. 실험에서 서로 다른 두 알고리즘이 어떻게 일치하는지에 대한 공정한 비교를 제공하기 위해 이러한 각 알고리즘의 작동 방식에 대한 컨텍스트를 제공해야합니다.
LSTM
LSTM은 알고리즘 출력에 대한 기능을 제공하는 많은 신경망으로 구성된 반복 신경망의 한 유형입니다. 예를 들어 중복 신호의 가중치를 줄 이도록 훈련된 망각 네트워크(forget network)가 있습니다.
반복되는 신경망의 복잡한 위치는 네트워크가 과거의 "기억"(과거 데이터)을 회상 할 수 있도록합니다. 이 기능을 사용하면 현재 데이터 포인트와 과거 데이터 포인트 사이의 연결을 쉽게 생성 할 수 있으므로 네트워크가 시간이 지남에 따라 재생되는 패턴을 찾을 수 있습니다.
CNN
CNN은 20세기 후반에 처음으로 인식된 다층 퍼셉트론의 첫 번째 혁신이었습니다. 입력 데이터를 따라 적용되는 필터로 구성됩니다. 이렇게하면 데이터가 더 작은 해상도로 효과적으로 압축됩니다. CNN은 필수 정보를 잃지 않고 전체 크기 이미지를 더 작은 해상도로 변환하도록 훈련되었습니다. 기본적으로 입력 데이터의 노이즈를 제거 할 수 있으므로 기본 신경망을 통해 공급 될 수 있습니다.
이 공간 인식은 2D 공간에서 작동 할뿐만 아니라 3D 공간 (시간에 따른 이미지로 구성된 비디오) 그리고 1차원 시계열 데이터에도 적용됩니다. 이러한 다재다능 함이 CNN을 매우 유용하게 만드는 요소입니다.
파이썬을 이용한 모델 개발
지난 20년 동안의 애플(Ticker: AAPL) 주가 예측을 LSTM과 CNN을 이용하여 구현해 보겠습니다. 평가는 프로그램의 손실 값을 기반으로 평가되고 테스트 데이터에 대한 네트워크의 예측을 관찰해보겠습니다.
스텝1. 데이터 준비
import yfinance
import numpy as np
df = yfinance.download('AAPL','2000-1-1','2020-1-1')
df = df.drop(['Volume'],1).drop(['Adj Close'],1)위의 파이썬 코드는 지난 20년 동안 애플(AAPL) 주식가 데이터를 추출합니다. 이 데이터 세트에 다양한 컬럼 값이 있으며, 거래량(Volume)과 조정된 종가(Adj Close) 데이터는 제거하겠습니다.
def normalize_data(dataset):
cols = dataset.columns.tolist()
col_name = [0]*len(cols)
for i in range(len(cols)):
col_name[i] = i
dataset.columns = col_name
dtypes = dataset.dtypes.tolist()
minmax = list()
for column in dataset:
dataset = dataset.astype({column: 'float32'})
for i in range(len(cols)):
col_values = dataset[col_name[i]]
value_min = min(col_values)
value_max = max(col_values)
minmax.append([value_min, value_max])
for column in dataset:
values = dataset[column].values
for i in range(len(values)):
values[i] = (values[i] - minmax[column][0]) / (minmax[column][1] - minmax[column][0])
dataset[column] = values
dataset[column] = values
return dataset,minmax
dataset,minmax = normalize_data(df)
print(df.values)
values = dataset.values이 함수는 데이터 프레임 내에서 데이터 세트를 정규화하기위한 포괄적인 함수입니다. 모든 열의 이름을 숫자로 바꾸는 일반적인 방법에 유의하십시오. 따라서 데이터 프레임의 크기에 관계없이 적용될 수 있습니다.
def split_sequences(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
end_ix = i + n_steps
if end_ix > len(sequence)-1:
break
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return np.array(X), np.array(y)
def data_setup(n_steps, n_seq,sequence):
X, y = split_sequences(sequence, n_steps)
n_features = X.shape[2]
X = X.reshape((len(X),n_steps, n_features))
new_y = []
for term in y:
new_term = term[-1]
new_y.append(new_term)
return X, np.array(new_y), n_features
n_steps = 10
n_seq = 10000
rel_test_len = 0.1
X,y,n_features = data_setup(n_steps,n_seq,values)
X = X[:-1]
y = y[1:]
X_test,y_test = X[:int(len(X)*rel_test_len)],y[:int(len(X)*rel_test_len)]
X_train,y_train = X[int(len(X)*rel_test_len):],y[int(len(X)*rel_test_len):]
X.shape
이 스크립트는 시퀀스를 데이터 세트로 변환합니다. X 값은 종가를 제외한 다른 모든 열이며, 이는 y 값이됩니다. 이것은 컴퓨터가 종가를 예측하기 위해 주식 시세를 사용할 것임을 의미합니다.
또한 데이터를 훈련 및 테스트 데이터로 분할했습니다. 두 데이터 세트 간의 분할은 10–90 분할이고 데이터의 90 %는 학습에 사용되며 10 %는 학습에 사용됩니다.
스텝2. LSTM
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.layers import LSTM
model = Sequential()
model.add(LSTM(64, activation=None, input_shape=(10,4), return_sequences = True))
model.add(LSTM(32, activation=None, return_sequences = True))
model.add(Flatten())
model.add(Dense(100, activation=None))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mse', optimizer='adam')꽤 자명하다! 내림차순 셀 수가 있는 기본 LSTM 네트워크. 데이터가 0–1 범위 내에서 정규화되었으며, 최종 레이어는 Sigmoid를 사용했습니다.
스텝3. 1D CNN
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.layers.convolutional import Conv1D
from keras.layers.convolutional import MaxPooling1D
model = Sequential()
model.add(Conv1D(filters=128, kernel_size=3, activation='relu', input_shape=(10,4)))
model.add(Conv1D(filters=64, kernel_size=3, activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(Flatten())
model.add(Dense(100, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='mse', optimizer='adam')
이것은 출력 계층 앞에 100개의 뉴런 계층이 있는 1차원 배열에 대한 내림차순 컨벌루션 신경망입니다. Relu 함수의 큰 출력은 LSTM을 오버로드 할 수 있으므로 Relu는 LSTM이 아닌 CNN에 사용됩니다.
스텝4. 네트워크 훈련
import os
from keras import callbacks
epochs = 5000
verbosity = 2
dirx = 'XXXXXXX'
os.chdir(dirx)
h5 = 'network.h5'
checkpoint = callbacks.ModelCheckpoint(h5,
monitor='val_loss',
verbose=0,
save_best_only=True,
save_weights_only=True,
mode='auto',
period=1)
callback = [checkpoint]
json = 'network.json'
model_json = model.to_json()
with open(json, "w") as json_file:
json_file.write(model_json)
history = model.fit(X_train,
y_train,
epochs=epochs,
batch_size=len(X_train) // 4,
validation_data = (X_test,y_test),
verbose=verbosity,
callbacks=callback)체크 포인트 콜백을 사용하는 것이 모델의 최종 평가에 매우 유용하다는 것을 발견했습니다. 특히 신경망의 최상의 가중치를 저장 한 후에는 더욱 그렇습니다.
from keras.models import load_model, model_from_json
def load_keras_model(optimizer):
dirx = 'XXXXXXX'
os.chdir(dirx)
json_file = open('Convnet.json', 'r')
loaded_model_json = json_file.read()
json_file.close()
model = model_from_json(loaded_model_json)
model.compile(optimizer=optimizer, loss='mse')
model.load_weights('Convnet.h5')
return model
model = load_keras_model('adam')
여기서 로드된 가중치는 이 함수를 사용하여 동일한 데이터 세트에서로드 할 수 있습니다.
스텝5. 결과 시각화
model.evaluate(X_test,y_test)
이 코드 한 줄은 데이터 세트에서 검색된 테스트 데이터에 대한 MSE 값을 반환합니다.
from matplotlib import pyplot as plt
pred_test = model.predict(X_test)
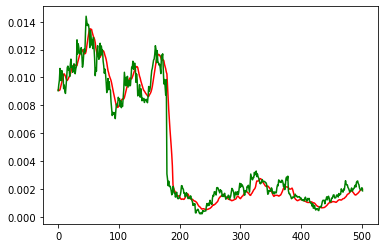
plt.plot(pred_test,'r')
plt.plot(y_test,'g')
모델의 손실 값은이 플로팅 기능과 쌍을 이루어 주식 거래 데이터 세트에서 어떤 모델이 더 잘 수행되었는지 확인합니다. 플로팅 기능이 필요한 이유는 무엇입니까? 손실 값이 낮다고해서 알고리즘이 의도한 방식으로 수렴된 것은 아닙니다. 모델의 예측과 데이터 세트 간의 정렬을 관찰하면 모델이 실제로 신뢰할 수있는 관계를 찾은 방법과 여부에 대한 더 많은 통찰력을 얻을 수 있습니다.
결과
두개의 모델을 통해 네트워크를 훈련하는데 소요되는 시간:
CNN: 20m 25s
LSTM: 34m 28s다음은 CNN과 LSTM의 손실 값 비교입니다.
CNN: 9.132824629887182e-07
LSTM: 9.205878086504526e-07
LSTM 및 CNN에 의해 생성된 예측치 시각화:

결론
결과에서 거의 똑같이 일치하는 것 같습니다! 품질면에서 차이는 가장 작은 마진으로 내려갑니다. 그러나 훈련 시간과 계산 강도 측면에서 CNN이 우수합니다.
CNN이 LSTM보다 약간 더 잘 작동했지만 데이터 세트를 살펴보고 데이터 세트에서 잘 작동하도록 모형의 하이퍼 파라미터를 조정하면 두 모형의 성능이 뒤바뀔 수도 있습니다.
참고) 위 글의 원문은 아래 링크에서 읽어 볼 수 있습니다.
medium.com/hands-on-data-science/lstms-or-cnns-for-predicting-stock-prices-2974c0c8c4ef
LSTMs or CNNs for predicting Stock Prices?
Should we abandon LSTMs for CNNs?
medium.com
'데이터과학 > 데이터 분석 실습' 카테고리의 다른 글
| [SQL] row_number() vs. count(1) (0) | 2022.06.04 |
|---|---|
| Step-by-step understanding LSTM Autoencoder layers (1) | 2021.09.08 |
| 머신 러닝 기반의 금융 사기 탐지: 불균형 데이터를 다루는 방법 (0) | 2021.01.23 |
| 기계 학습 기반의 신용평가 모형 개발과 신용 점수 계산 (1) | 2021.01.20 |
| AWS SageMaker를 이용해서 모델 빌드, 배포, 예측하기 (2) | 2021.01.19 |



