이번 포스팅은 아래 글을 번역한 것임을 밝힙니다.
https://towardsdatascience.com/step-by-step-understanding-lstm-autoencoder-layers-ffab055b6352
Step-by-step understanding LSTM Autoencoder layers
Here we will break down an LSTM autoencoder network to understand them layer-by-layer. We will go over the input and output flow between…
towardsdatascience.com
이번 글에서는 LSTM Autoencoder 네트워크를 계층별로 이해하기 위해 전체 구조를 분해할 것입니다. 계층 간의 입력 및 출력 흐름을 살펴보고 LSTM Autoencoder를 일반 LSTM 네트워크와 비교해 보겠습니다.
딥러닝의 LSTM은 조금 복잡하며, LSTM 중간 계층과 그 설정을 이해하는 것은 간단하지 않습니다. 예를 들어 return_sequences, RepeatVector, 그리고 TimeDistributed 레이어의 사용 방법을 정확히 이해하지 못하면, 혼돈해서 사용하는 경우도 있습니다.
LSTM Autoencoder 네트워크를 계층별로 이해하기 위해 전체 구조를 분해할 것입니다. 이번 포스팅에서 설명하는 네트워크는 LSTM Autoencoder 이지만 널리 사용되는 seq2seq 네트워크의 구조 또한 LSTM Autoencoder와 유사합니다. 따라서 LSTM Autoencoder에 대한 대부분의 설명은 일반적인 seq2seq 네트워크에도 적용될 수 있음을 미리 말씀 드립니다.
이번 포스팅에서는 간단한 예시를 사용하여 다음의 항목들에 대해서 학습할 것입니다.
- return_sequences=True, RepeatVector(), 그리고 TimeDistributed()의 의미
- 각 LSTM 네트워크 계층의 입력 및 출력 이해
- 일반 LSTM 네트워크와 LSTM Autoencoder의 차이점
모델 구조의 이해
# lstm autoencoder to recreate a timeseries
import numpy as np
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import RepeatVector
from keras.layers import TimeDistributed
'''
A UDF to convert input data into 3-D
array as required for LSTM network.
'''
def temporalize(X, y, lookback):
output_X = []
output_y = []
for i in range(len(X)-lookback-1):
t = []
for j in range(1,lookback+1):
# Gather past records upto the lookback period
t.append(X[[(i+j+1)], :])
output_X.append(t)
output_y.append(y[i+lookback+1])
return output_X, output_y예시 데이터 생성
# define input timeseries
timeseries = np.array([[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9],
[0.1**3, 0.2**3, 0.3**3, 0.4**3, 0.5**3, 0.6**3, 0.7**3, 0.8**3, 0.9**3]]).transpose()
timesteps = timeseries.shape[0]
n_features = timeseries.shape[1]
timeseries
LSTM 네트워크에 필요한 대로 입력 데이터를 n_samples x timesteps x n_features로 재구성해야 합니다. 이 예에서 n_features는 2입니다. 우리는 timesteps = 3을 만들 것입니다. 그 결과 (입력 데이터에 9개의 행이 있기 때문에) n_samples는 5가 됩니다.
timesteps = 3
X, y = temporalize(X = timeseries, y = np.zeros(len(timeseries)), lookback = timesteps)
n_features = 2
X = np.array(X)
X = X.reshape(X.shape[0], timesteps, n_features)
X
LSTM Autoencoder 구조 이해하기
이제 LSTM Autoencoder 네트워크를 구축하고 아키텍처와 데이터 흐름을 시각화 할 것입니다. 또한 Autoencoder와의 차이점을 비교하고 대조하기 위해 일반 LSTM 네트워크를 살펴볼 것입니다.
LSTM Autoencoder 정의.
# define model
model = Sequential()
model.add(LSTM(128, activation='relu', input_shape=(timesteps,n_features), return_sequences=True))
model.add(LSTM(64, activation='relu', return_sequences=False))
model.add(RepeatVector(timesteps))
model.add(LSTM(64, activation='relu', return_sequences=True))
model.add(LSTM(128, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(n_features)))
model.compile(optimizer='adam', loss='mse')
model.summary()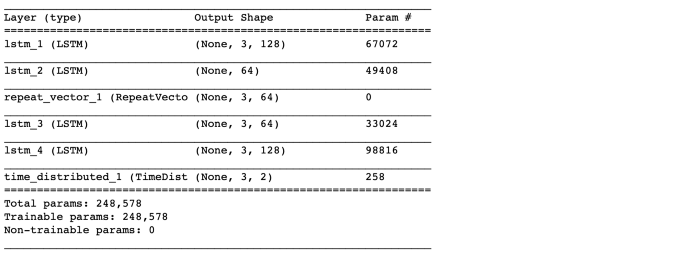
# fit model
model.fit(X, X, epochs=300, batch_size=5, verbose=0)
# demonstrate reconstruction
yhat = model.predict(X, verbose=0)
print('---Predicted---')
print(np.round(yhat,3))
print('---Actual---')
print(np.round(X, 3))
model.summary()는 모델 아키텍처의 요약을 제공합니다. 아래의 <그림1>은 모델 구조에 대해 더욱 깊이 있는 이해에 도움이 될 것입니다.

다이어그램은 한 데이터 샘플에 대한 LSTM Autoencoder 네트워크의 계층을 통한 데이터 흐름을 보여줍니다. 데이터 샘플은 데이터세트의 한 인스턴스입니다. 이 다이어그램을 통해서 아래의 내용을 알 수 있습니다.
- LSTM 네트워크는 2D 배열을 입력으로 사용합니다.
- LSTM의 한 레이어에는 타임스텝만큼 많은 셀이 있습니다.
- return_sequences=True 로 설정하면 타임스텝당 각 셀이 신호를 방출합니다.
- 이는 return_sequences의 True(그림2a) 대 False(그림2b)의 차이를 보여주는 그림2에서 더 명확해집니다.

- 그림2a에서 한 계층의 타임스텝 셀에서 오는 신호는 다음 계층의 동일한 타임스텝 셀에 수신됩니다.
- LSTM 자동 인코더의 인코더 및 디코더 모듈에서 그림2a와 같이 연속적인 LSTM 계층의 각 타임스텝 셀 간에 직접 연결을 갖는 것이 중요합니다.
- 그림2b에서 마지막 타임스텝 셀만 신호를 방출합니다. 따라서 출력은 벡터입니다.
- 그림2b와 같이 후속 레이어가 LSTM이면 RepeatVector(timesteps)를 사용하여 이 벡터를 복제하여 다음 레이어에 대한 2D 배열을 얻습니다.
- 후속 레이어가 Dense인 경우 변환이 필요하지 않습니다(Dense 레이어는 벡터를 입력으로 예상하기 때문)
다시 그림1로 돌아가 보겠습니다.
- 입력 데이터에는 3개의 시간 단계와 2개의 기능이 있습니다.
- 레이어 1인 LSTM(128)은 입력 데이터를 읽고 return_sequences=True이기 때문에 각각에 대해 3개의 시간 단계가 있는 128개의 기능을 출력합니다.
- 레이어 2인 LSTM(64)은 레이어 1에서 3x128 입력을 받아 기능 크기를 64로 줄입니다. return_sequences=False이므로 크기가 1x64인 기능 벡터를 출력합니다.
- 이 계층의 출력은 입력 데이터의 인코딩된 특징 벡터입니다.
- 이 인코딩된 특징 벡터는 추출되어 데이터 압축으로 사용되거나 다른 지도 또는 비지도 학습을 위한 특징으로 사용할 수 있습니다(다음 게시물에서 추출하는 방법을 볼 것입니다).
- 레이어 3인 RepeatVector(3)는 특징 벡터를 3번 복제합니다.
- RepeatVector 레이어는 인코더와 디코더 모듈 사이의 다리 역할을 합니다.
- 디코더의 첫 번째 LSTM 레이어에 대한 2D 배열 입력을 준비합니다.
- 디코더 계층은 인코딩을 펼치도록 설계되었습니다.
- 따라서 디코더 계층은 인코더의 역순으로 쌓입니다.
- 레이어 4, LSTM(64) 및 레이어 5, LSTM(128)은 각각 레이어 2와 레이어 1의 미러 이미지입니다.
- 레이어 6, TimeDistributed(Dense(2))가 출력을 얻기 위해 마지막에 추가됩니다. 여기서 "2"는 입력 데이터의 기능 수입니다.
- TimeDistributed 레이어는 이전 레이어에서 출력된 피처의 수와 동일한 길이의 벡터를 생성합니다. 이 네트워크에서 레이어 5는 128개의 기능을 출력합니다. 따라서 TimeDistributed 레이어는 128개의 긴 벡터를 만들고 2(= n_features)번 복제합니다.
- 레이어 5의 출력은 U로 표시되는 3x128 배열이고 레이어 6에서 TimeDistributed의 출력은 V로 표시되는 128x2 배열입니다. U와 V 간의 행렬 곱셈은 3x2 출력을 생성합니다.
- 네트워크 피팅의 목적은 이 출력을 입력에 가깝게 만드는 것입니다. 이 네트워크 자체는 입력 및 출력 차원이 일치하도록 했습니다.
LSTM Autoencoder와 일반 LSTM 네트워크 비교
위의 이해는 입력을 재구성하기 위해 구축된 일반 LSTM 네트워크와 비교할 때 더 명확해집니다.
# define model
model = Sequential()
model.add(LSTM(128, activation='relu', input_shape=(timesteps,n_features), return_sequences=True))
model.add(LSTM(64, activation='relu', return_sequences=True))
model.add(LSTM(64, activation='relu', return_sequences=True))
model.add(LSTM(128, activation='relu', return_sequences=True))
model.add(TimeDistributed(Dense(n_features)))
model.compile(optimizer='adam', loss='mse')
model.summary()
# fit model
model.fit(X, X, epochs=300, batch_size=5, verbose=0)
# demonstrate reconstruction
yhat = model.predict(X, verbose=0)
print('---Predicted---')
print(np.round(yhat,3))
print('---Actual---')
print(np.round(X, 3))

일반 LSTM 네트워크와 LSTM Autoencoder의 차이점
- 모든 LSTM 레이어에서 return_sequences=True를 사용하고 있습니다.
- 즉, 각 레이어는 각 시간 단계를 포함하는 2D 배열을 출력합니다.
- 따라서 중간 계층의 출력으로 1차원 인코딩된 특징 벡터가 없습니다. 따라서 샘플을 특징 벡터로 인코딩하는 것은 일어나지 않습니다.
이 인코딩 벡터가 없으면 재구성을 위한 일반 LSTM 네트워크를 LSTM 자동 인코더와 구별합니다. - 그러나 매개변수의 수는 Autoencoder와 일반 네트워크 모두에서 동일합니다.
- Autoencoder의 "추가 RepeatVector 레이어에는 추가 매개변수가 없기" 때문입니다.
- 가장 중요한 것은 두 네트워크의 재구성 정확도가 비슷하다는 것입니다.
생각해 보기
희귀 이벤트 분류를 위해 LSTM Autoencoder에서 논의된 이상 감지 접근 방식을 사용한 희귀 이벤트 분류는 희귀 이벤트를 감지하도록 LSTM Autoencoder를 훈련시키는 것입니다. Autoencoder 네트워크의 목적은 입력을 재구성하고 제대로 재구성되지 않은 샘플을 드문 이벤트로 분류하는 것입니다.
그림3과 같이 시계열 데이터를 재구성하기 위해 일반 LSTM 네트워크를 이용할 수도 있다는 것입니다.
'데이터과학 > 데이터 분석 실습' 카테고리의 다른 글
| [pyspark] GraphFrames 다루기 (2) | 2022.06.07 |
|---|---|
| [SQL] row_number() vs. count(1) (0) | 2022.06.04 |
| LSTM 또는 CNN을 이용한 주가 예측 (1) | 2021.01.31 |
| 머신 러닝 기반의 금융 사기 탐지: 불균형 데이터를 다루는 방법 (0) | 2021.01.23 |
| 기계 학습 기반의 신용평가 모형 개발과 신용 점수 계산 (1) | 2021.01.20 |



